urlparse库用于把url解析为各个组件,支持file,ftp,http,https, imap, mailto, mms, news, nntp, prospero, rsync, rtsp, rtspu, sftp, shttp, sip, sips, snews, svn, svn+ssh, telnet等几乎所有的形式。根据其官网的说明,在Python3.0中,此库已经更名为urllib.parse了。
官方文档地址:http://docs.python.org/library/urlparse.html
函数说明
1. urlparse()函数
from urlparse import urlparse
urlparse(urlstring[, scheme[, allow_fragments]])
该函数将一个url字符串分解为6个元素,以元祖的形式返回。这与URL的一般结构相关: scheme://netloc/path;parameters?query#fragment.解析得到的每个元素都是一个字符串,有的元素可能为空.除了返回这6个元素外,返回的对象还包含了一些属性:username、password、hostname、port. 例如:
>>> from urlparse import urlparse
>>> o = urlparse('https://lifeblog.ren/about.html')
>>> o
ParseResult(scheme='https',netloc='lifeblog.ren', path='/about.html', params='', query='', fragment='')
>>> o.port
80
>>> o.hostname
'lifeblog.ren'
注意一点,若要得到正确的netloc值,则url必须以//开头,否则会被归到path值里去.例如:
>>> urlparse('//https://lifeblog.ren/about.html')
ParseResult(scheme='', netloc=lifeblog.ren', path='/about.html', params='', query='', fragment='')
>>> urlparse('https://lifeblog.ren/about.html')
ParseResult(scheme='', netloc='', path='lifeblog.ren/about.htmll', params='', query='', fragment='')
其实,返回的结果是tuple子类的一个实例.该类具有如下的只读属性:
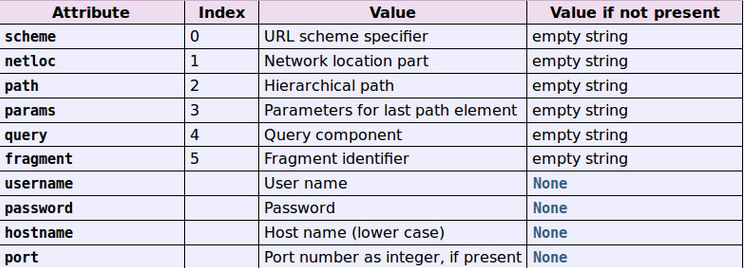
3.urlsplit(urlstring[, scheme[, allow_fragments]])此函数与urlparse()类似,不过返回的是一个5元素的元祖,不包括params。
4.urlunsplit(parts)函数此函数是将urlsplit函数分解的元素再组合起来。
5.urljoin(base,url[,allow_fragments]):基于一个base URL和另一个URL构造一个绝对URL.例如:
>>> from urlparse import urljoin
>>> urljoin('https://lifeblog.ren/about.html', 'FAQ.html')
'https://lifeblog.ren/about.html'
注意,如果参数中的url为一个绝对路径的URL(即以//或scheme://开始),那么url的host name 和(或)scheme将会出现在结果中.例如:
>>> urljoin('https://lifeblog.ren/about.html', '//lifeblog.ren/about.html')
'https://lifeblog.ren/about.html'
6.其它的方法不再一一介绍.